Benchmarking Neo4j
Posted on May 19, 2019 in coding-fun • 4 min read
Introduction
Neo4j is a graph database implementation. It's used for creating large graphs to efficiently create and query various relationships. For an explanation on the differences between graph databases and relational database (like MySQL and PostgreSQL), see https://neo4j.com/developer/graph-db-vs-rdbms/.
I required Neo4j for one of my projects and one of the issues we were running into was that it was taking a long time to create our massive graphs (10s of millions of nodes with 100s of millions of edges). We had read that Neo4j was completely capable of handling graphs of this size (and larger) but couldn't figure out why our methods of creating our graphs were so slow.
Unfortunately I couldn't find anyone online who had done benchmarking on creating various sizes of graphs using the different ways of creating a Neo4j graph (which I will explain below). So I thought this was a great opportunity to write some code to test the various ways of creating Neo4j graphs and share my results with anyone interested in answering the same question.
Creating Neo4j Graphs the "Normal" Way
When you first read Neo4j tutorials on creating graphs, they probably mention something about MERGE for creating Nodes and CREATE for creating Edges. MERGE is helpful because it will simultaneously check and create a unique node if it does not exist. If MERGE didn't exist, you would have to create some MATCH condition to say "if this node doesn't exist yet, create it". In the graphs for my project, all of the nodes and edges had to be unique.
Our first implementation just contained those simple queries: Create a node and create an edge. That ended up being very slow (taking 40 seconds to create a graph with 1000 nodes and 1000 edges). So the second thing we tried was creating each node and edge in the same query (as opposed to creating each individual node and edge within individual queries). Another thing we added was creating all nodes and edges first and then creating the remaining unconnected nodes at the end. We also tried adding an INDEX to each node as well. This implementation was faster than the first, but still too slow for our needs. Our test graph (1000 nodes and 1000 edges) took roughly 30 seconds to create.
Then we found a query called a CONSTRAINT which allows the user to create some logical rule for the graph database to follow. For us, it was to only accept unique nodes and edges. But this third implementation also wasn't very fast. Finally we tried getting rid of both INDEX and CONSTRAINT to see if that was bogging anything down, but to no avail. Our fourth implementation had failed us.
We then created a batch implementation where we would batch multiple queries into one (a similar technique used on relational databases). Unfortunately this ended up being slower than our first implementation. Needless to say we were frustrated, but knew there must be a solution that Neo4j provides us.
Pause for Consideration
These timings may sound fast to someone with sufficiently small graphs, but it would take us nearly 10 days to create a single graph with 10s of millions of nodes and 100s of millions of edges (which was way too slow for our needs). Our particular application required streaming graph data to our server where we would need to create these large graphs in realtime (and 10 days was barely realtime). Also we noticed that creating the graphs slowed over time as the graph size grew, so our guestimate of 10 days was actually much smaller compared to what we experienced in reality.
Creating Neo4j Graphs the Efficient Way
After scouring the Internet for a day or so, we happened upon two query methods used to create graphs quickly: UNWIND and LOADCSV.
One can think of UNWIND as the proper way to use batching in Neo4j (like we had tried to emulate above for batching for relational databases). Immediately we saw fantastic results. The time it took to create a graph decreased by an order of magnitude (our 1000 node 1000 edge graph took seconds). Unfortunately during our evaluation of our project, it still was slower than realtime after a day or so of running it with our streaming data. It eventually caught up, but after several days of letting it run after our streaming data stopped after 2 weeks.
Finally we found the best implementation. LOADCSV is by far the fastest way to create large graphs. It had been touted as being able
to create a 30 million node graph in minutes https://neo4j.com/blog/import-10m-stack-overflow-questions/. When we implemented using it ourselves it decreased our graph creation time down to 0.17 seconds. Another order of magnitude difference!
But we were also curious in knowing how much different types and sizes of graphs affected the creation time. Below are various timing bar charts of our results:
10 nodes, 10 edges
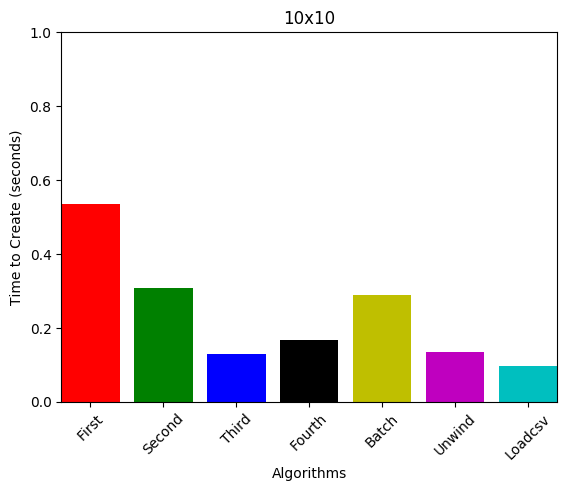
1000 nodes, 1000 edges
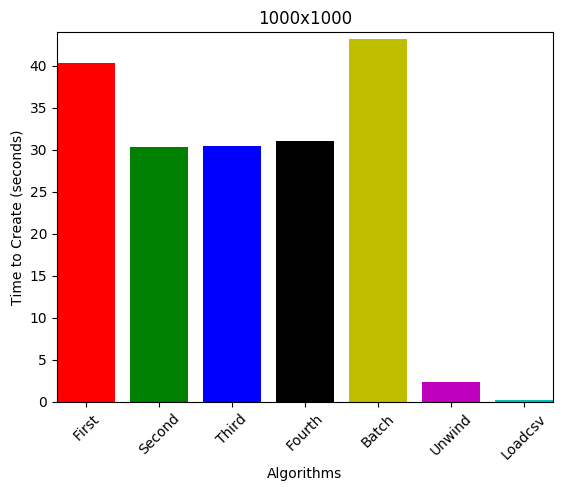
1000 nodes, 10 edges (sparse graph)
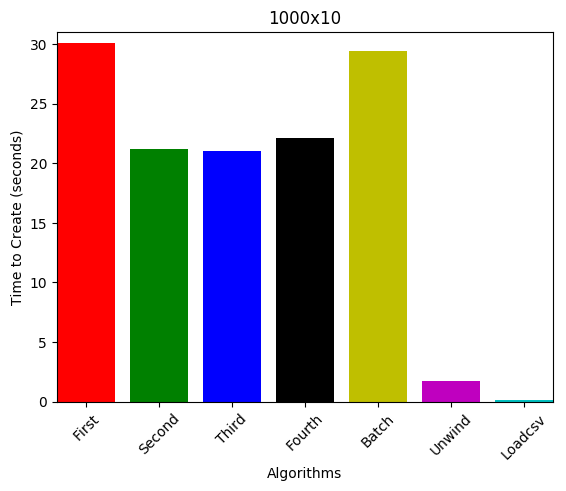
10 nodes, 1000 edges (dense graph)
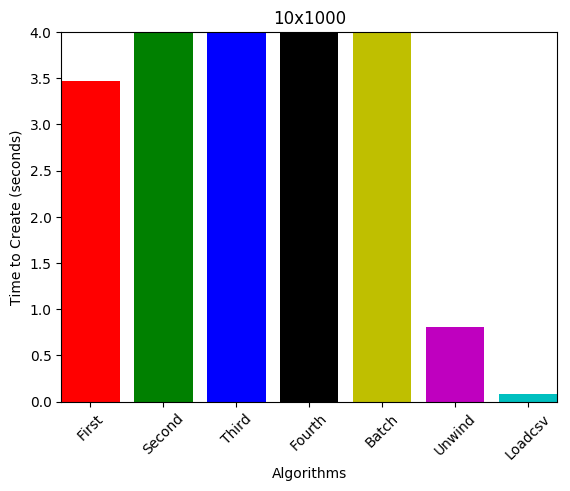
Conclusion
If you're creating a large graph in Neo4j, use LOADCSV.
You can check out all of my source code used to perform my experiments to test for yourself: https://github.com/evandowning/neo4j-benchmark